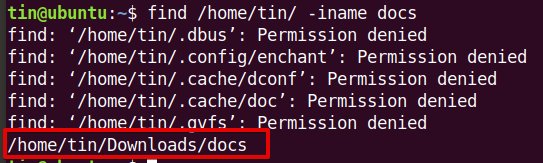
7 linux grep or, grep and, grep not operator examples
Содержание:
- ОБРАЗЕЦ
- Example usage
- Регулярное выражение Grep
- Regular expressions
- Опции
- Синтаксис
- Как с awk или sed выбрать строки между двумя шаблонами, которые могут встречаться несколько раз
- Оглавление
- Опции — расширения GNU
- Grep AND
- Использование egrep в Linux
- СИНТАКСИС GREP
- Использование egrep в Linux
- ОПЦИИ
- Basic vs. extended regular expressions
- Синтаксис
- Character classes and bracket expressions
- Поиск полных слов
- Добавление контекста
ОБРАЗЕЦ
GIST | Простейший поиск всех строк, в которых есть текст «Adams». При оформлении этого и последующих примеров будем придерживаться следующего порядка: сверху параметры командной строки, внизу стандартные потоки слева ввода и справа вывода .
Adams
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801
Команда «grep» имеет внушительное количество опций, которые можно указать при запуске. С помощью этих опций можно делать много полезных вещей и при этом в принципе даже не обязательно хорошо разбираться в синтаксисе регулярных выражений.
Example usage
Let’s say want to quickly locate the phrase «our products» in HTML files on your machine. Let’s start by searching a single file. Here, our PATTERN is «our products» and our FILE is product-listing.html.

A single line was found containing our pattern, and grep outputs the entire matching line to the terminal. The line is longer than our terminal width so the text wraps around to the following lines, but this output corresponds to exactly one line in our FILE.
Note
The PATTERN is interpreted by grep as a regular expression. In the above example, all the characters we used (letters and a space) are interpreted literally in regular expressions, so only the exact phrase will be matched. Other characters have special meanings, however — some punctuation marks, for example. For more information, see: Regular expression quick reference.
If we use the —color option, our successful matches will be highlighted for us:

Viewing line numbers of successful matches
It will be even more useful if we know where the matching line appears in our file. If we specify the -n option, grep will prefix each matching line with the line number:

Our matching line is prefixed with «18:» which tells us this corresponds to line 18 in our file.
Performing case-insensitive grep searches
What if «our products» appears at the beginning of a sentence, or appears in all uppercase? We can specify the -i option to perform a case-insensitive match:

Using the -i option, grep finds a match on line 23 as well.
Searching multiple files using a wildcard
If we have multiple files to search, we can search them all using a wildcard in our FILE name. Instead of specifying product-listing.html, we can use an asterisk («*«) and the .html extension. When the command is executed, the shell expands the asterisk to the name of any file it finds (in the current directory) which ends in «.html«.
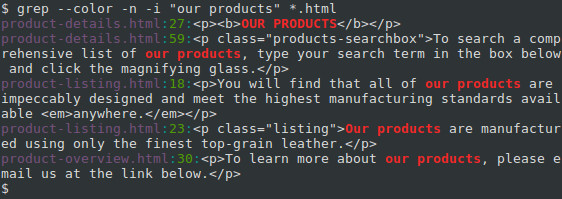
Notice that each line starts with the specific file where that match occurs.
Recursively searching subdirectories
We can extend our search to subdirectories and any files they contain using the -r option, which tells grep to perform its search recursively. Let’s change our FILE name to an asterisk («*«), so that it matches any file or directory name, and not only HTML files:
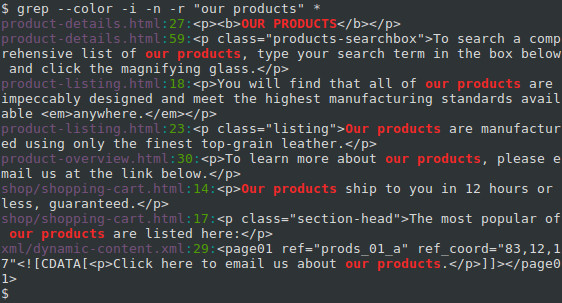
This gives us three additional matches. Notice that the directory name is included for any matching files that are not in the current directory.
Using regular expressions to perform more powerful searches
The true power of grep is that it can match regular expressions. (That’s what the «re» in «grep» stands for). Regular expressions use special characters in the PATTERN string to match a wider array of strings. Let’s look at a simple example.
Let’s say you want to find every occurrence of a phrase similar to «our products» in your HTML files, but the phrase should always start with «our» and end with «products». We can specify this PATTERN instead: «our.*products».
In regular expressions, the period («.«) is interpreted as a single-character wildcard. It means «any character that appears in this place will match.» The asterisk («*«) means «the preceding character, appearing zero or more times, will match.» So the combination «.*» will match any number of any character. For instance, «our amazing products«, «ours, the best-ever products«, and even «ourproducts» will match. And because we’re specifying the -i option, «OUR PRODUCTS» and «OuRpRoDuCtS will match as well. Let’s run the command with this regular expression, and see what additional matches we can get:
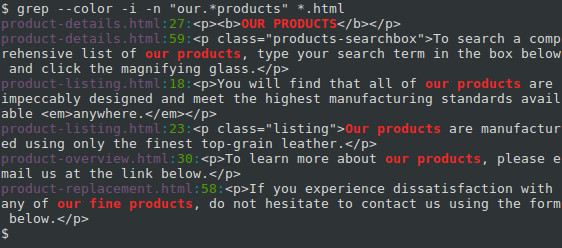
Here, we also got a match from the phrase «our fine products«.
Grep is a powerful tool to help you work with text files, and it gets even more powerful when you become comfortable using regular expressions.
Регулярное выражение Grep
Регулярное выражение или регулярное выражение — это шаблон, который соответствует набору строк. Шаблон состоит из операторов, конструирует буквальные символы и метасимволы, которые имеют особое значение. GNU поддерживает три синтаксиса регулярных выражений: базовый, расширенный и Perl-совместимый.
В своей простейшей форме, когда тип регулярного выражения не указан, интерпретирует шаблоны поиска как базовые регулярные выражения. Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр (или ).
В реализации GNU нет функциональной разницы между базовым и расширенным синтаксисами регулярных выражений. Единственная разница в том, что в базовых регулярных выражениях метасимволы , , , , , и интерпретируются как буквальные символы. Чтобы сохранить особое значение метасимволов при использовании основных регулярных выражений, символы должны быть экранированы обратной косой чертой ( ). Мы объясним значение этих и других мета-символов позже.
Как правило, вы всегда должны заключать регулярное выражение в одинарные кавычки, чтобы избежать интерпретации и расширения метасимволов оболочкой.
Regular expressions
A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, using various operators to combine smaller expressions.
grep understands three different versions of regular expression syntax: «basic» (BRE), «extended» (ERE) and «perl» (PRCE). In GNU grep, there is no difference in available functionality between basic and extended syntaxes. In other implementations, basic regular expressions are less powerful. The following description applies to extended regular expressions; differences for basic regular expressions are summarized afterwards. Perl regular expressions give additional functionality.
The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any metacharacter with special meaning may be quoted by preceding it with a backslash.
The period (.) matches any single character.
Опции
-0- Использует во входном потоке символ-разделитель NULL («\0») вместо «пробела» и «перевода строки», хорошо сочетается с опцией -print0 команды find
-l -Выполнять команду для каждой группы из заданного числа непустых строк аргументов, прочитанных со стандартного ввода. Последний вызов команды может быть с меньшим числом строк аргументов. Считается, что строка заканчивается первым встретившимся символом перевода строки, если только перед ним не стоит пробел или символ табуляции; пробел/табуляция в конце сигнализируют о том, что следующая непустая строка является продолжением данной. Если число опущено, оно считается равным 1. Опция -l включает опцию -x.
-I Режим вставки: команда выполняется для каждой строки стандартного ввода, причём вся строка рассматривается как один аргумент и подставляется в начальные_аргументы вместо каждого вхождения цепочки символов зам_цеп. Допускается не более 5 начальных_аргументов, содержащих одно или несколько вхождений зам_цеп. Пробелы и табуляции в начале вводимых строк отбрасываются. Сформированные аргументы не могут быть длиннее 255 символов. Если цепочка зам_цеп не задана, она полагается равной { }. Опция -I включает опцию -x.
-n Выполнить команду, используя максимально возможное количество аргументов, прочитанных со стандартного ввода, но не более заданного числа. Будет использовано меньше аргументов. Если их общая длина превышает размер (см. ниже опцию -s). Или если для последнего вызова их осталось меньше, чем заданное число. Если указана также опция -x, каждая группа из указанного числа аргументов должны укладываться в ограничение размера, иначе выполнение xargs прекращается.
-t Режим трассировки: команда и каждый построенный список аргументов перед выполнением выводится в стандартный поток ошибок.
-p Режим с приглашением: xargs перед каждым вызовом команды запрашивает подтверждение. Включается режим трассировки (-t), за счет чего печатается вызов команды, который должен быть выполнен, а за ним — приглашение ?…. Ответ y (за которым может идти что угодно) приводит к выполнению команды; при каком-либо другом ответе, включая возврат каретки, данный вызов команды игнорируется.
-x Завершить выполнение, если очередной список аргументов оказался длиннее, чем размер (в символах). Опция -x включается опциями -i и -l. Если ни одна из опций -i, -l или -n не указана, общая длина всех аргументов должна укладываться в ограничение размера.
-s Максимальный общий размер (в символах) каждого списка аргументов установить равным заданному размеру. Размер должен быть положительным числом, не превосходящим 470 (подразумеваемое значение). При выборе размера следует учитывать, что к каждому аргументу добавляется по одному символу; кроме того, запоминается число символов в имени команды.
-e Цепочка символов лконф_цеп считается признаком логического конца файла. Если опция -e не указана, признаком конца считается подчеркивание (_). Опция -e без лконф_цеп аннулирует возможность устанавливать логический конец файла (подчеркивание при этом рассматривается как обычный символ). Команда xargs читает стандартный ввод до тех пор, пока не дойдет до конца файла или не встретит цепочку лконф_цеп.
Синтаксис
Рассмотрим синтаксис.
grep шаблон
Или так:
Команда | grep шаблон
Здесь под параметрами понимаются аргументы, с помощью которых настраивается поиск и вывод на экран. Например нужно найти слово «линукс», и не учитывать регистр при поиске. Тогда нужно использовать опцию «-i».
Шаблон — это выражение или строка.
Имя файла — где искать.
Основные параметры:
—help. Вывести справочную информацию.
-i. Не учитывать регистр при поиске.
-V. Узнать текущую версию.
-v. Инвертированный поиск.
-s. Не выводить на экран сообщения об ошибкам. Например сообщение о несуществующих файлах.
-r. Поиск в каталогах, подкаталогах или рекурсивный grep.
-w. Искать как слово с пробелами.
-с. Опция считает количество вхождений (счетчик).
-e. Регулярные выражения.
Примеры
Найдем все файлы в текущей директории где встречается слово «linux».
grep linux ./*
Здесь:
- linux — слово которое нужно искать;
- точка — текущая директория;
- звездочка — искать во всех файлах.
Чтобы начать поиск без учета регистра необходимо добавить аргумент «-i». В нашем примере получится так:
grep -i linux ./*
Поиск в конкретном документе. Для примера найдем в документе «test» слово «хороший». Для этого с помощью утилиты «cd» зайдем в текущую директорию, где лежит файл «test». В моем случаи он находится в домашнем каталоге, я ввожу просто «cd».
grep хороший test
Здесь:
- хороший — слово которое нужно найти;
- test — файл, где искать.
Рекурсивный поиск. Чтобы найти определенный текст в определенной директории, используют рекурсивный поиск. Для этого необходимо использовать параметр «-r». Найдем слово «vseprolinux» в домашнем каталоге root и его подкаталогах.
grep -r vseprolinux /etc/root
Найдем три слова сразу в одной строке «все про Линукс». Для этого будем использовать вертикальную черту и введет «grep» три раза.
grep «все» test | grep «про» | grep «Линукс»
Команда grep может сообщить сколько раз встречается слово. Нам поможет опция -с. Посчитаем сколько раз встречается слово «site» в документе «file».
grep -c site file
Как видно на скриншоте выше, в файле «file» три раза встречается слово «site». Однако команда также считает выражение «mysite» за «site». Как сделать чтобы mysite не попал под счетчик? Добавим опцию «-w.»
grep -cw site file
Регулярные выражения.
Регулярные выражение в утилите «grep» — это мощная функция, которая расширяет возможности поиска. Чтобы активировать эту функцию или режим, используется аргумент «-e».
Символы в выражениях:
- $ — конец строки;
- ^ — начало строки;
- [] — указывается диапазон значений или конкретные через запятую.
Найдем цифры 1-5 в документе «file».
grep file
В скобках написано диапазон значений от одного до пяти, также можно написать конкретные значения через запятую, так:
Как с awk или sed выбрать строки между двумя шаблонами, которые могут встречаться несколько раз
Могу ли я используя awk или sed выбрать строки, которые встречаются между двумя различными шаблонами маркеров? Может быть несколько секций, отмеченных этими шаблонами.
Например, допустим есть файл, содержащий:
abc def1 ghi1 jkl1 mno abc def2 ghi2 jkl2 mno pqr stu
Начальным паттерном является abc, а конечным паттерном является mno, мне нужно, чтобы вывод был таким:
def1 ghi1 jkl1 def2 ghi2 jkl2
Есть ли способ в sed или awk сделать так, чтобы находилось не единичное совпадение, а чтобы поиск повторялся пока не будет достигнут конец файла?
Решение:
Нужно использовать awk с флагом, который будет запускать вывод когда необходимо:
awk '/abc/{flag=1;next}/mno/{flag=0}flag' ФАЙЛ
def1
ghi1
jkl1
def2
ghi2
jkl2
Как это работает?
- /abc/ совпадает со строками, имеющими этот текст, также делает /mno/.
- /abc/{flag=1;next} устанавливает flag, когда найден текст abc. Затем эта строка пропускается.
- /mno/{flag=0} убирает flag, когда найдено mno.
- Конечный flag — это шаблон с дефолтным действием, которым является print $0: если флаг равен 1, то печатается строка. Таким образом, он напечатает все строки, появившиеся с момента появления abc и до следующего mno. Это также напечатает строки от последнего совпадения abc до конца файла.
Более детальное описание и примеры, вместе со случаями, когда паттерны показываются или нет, будут ниже.
Если вы хотите, чтобы печаталось всё между, а также сами паттерны, тогда вы можете использовать:
awk '/abc/{a=1}/mno/{print;a=0}a' ФАЙЛ
Или так:
awk '/abc/{a=1} a; /mno/{a=0}' ФАЙЛ
Или даже так:
awk '/abc/,/mno/' ФАЙЛ
Используя sed:
sed -n -e '/^abc$/,/^mno$/{ /^abc$/d; /^mno$/d; p; }'
Опция -n означает не печатать по умолчанию (эта опция разъяснена выше).
Шаблон ищет строки, содержащие только с abc до только mno, затем выполняет действия в { … }.
Первое действие удаляет строку abc, второе удаляет строку mno, а p печатает оставшиеся строки. Вы можете расслабить регулярные выражения по мере необходимости. Любые строки за пределами abc..mno просто не печатаются.
Оглавление
1. Описание программ grep
2. Вызов программы grep
3. Справка по команде grep
4 Опции grep
4.1 Общая информация о программе
4.2 Выбор типа регулярного выражения
4.3 Управление работой регулярных выражений
4.4 Управление выводом
4.5 Управление префиксом выходной строки
4.6 Управление контекстными строками
4.7 Выбор файлов и директорий
4.8 Остальные опции
5. Регулярные выражения
5.1 Фундаментальная структура
5.2 Классы символов и Выражения в квадратных скобках
5.3 Анкоры
5.4 Символы с обратным слешем и Специальные выражения
5.5 Повторения
5.6 Объединение регулярных выражений
5.7 Альтернативы в регулярных выражениях
5.8 Приоритет
5.9 Обратные ссылки и Подвыражения
Базовые и расширенные регулярные выражения
6. Переменные окружения grep
7. Статус выхода
8. Примеры использования grep
Опции — расширения GNU
Опции
-A —after-context=ЧИСЛО_СТРОК
-B —before-context=ЧИСЛО_СТРОК
-C —context=ЧИСЛО_СТРОК
С этими тремя опциями мы уже познакомились в четвертой Хитрости, они позволяют посмотреть соседние строки. -A: количество строк после совпадения с ОБРАЗЦОМ,
-B: количество строк перед совпадением, и -C: количество строк вокруг совпадения.
Опция —colour
Выделяет найденные строки цветом. Значения КОГДА могут быть: never (никогда), always (всегда), или auto. Пример:
grep -o 'английскими' --color grep-ru.txt английскими
Опция -D ДЕЙСТВИЕ
—devices=ДЕЙСТВИЕ
Если исследуемый файл является файлом устройства, FIFO (именованным каналом) или сокетом, то следует применять эту опцию. ДЕЙСТВИЙ всего два: read (прочесть), и skip (пропустить). Если вы указываете ДЕЙСТВИЕ read (используется по умолчанию), то программа попытается прочесть специальный файл, как если бы он был обычным файлом; если указываете ДЕЙСТВИЕ skip, то файлы устройств, FIFO и сокеты будут молча проигнорированы.
Опция -d ДЕЙСТВИЕ
—directories=ДЕЙСТВИЕ
Если входной файл является директорией, то используйте эту опцию. ДЕЙСТВИЕ read (прочесть) попытается прочесть директорию как обычный файл (некоторые ОС и файловые системы запрещают это; тогда появятся соответствующие сообщения, либо директории молча пропустят). Если ДЕЙСТВИЕ skip (пропустить), то директории будут молча проигнорированы. Если ДЕЙСТВИЕ recurse (рекурсивно), то grep будет просматривать все файлы и субдиректории внутри заданного каталога рекурсивно. Это эквивалент опции -r, с которой мы уже познакомились.
—with-filename
Выдает имя файла для каждого совпадения с ОБРАЗЦОМ. Мы успешно делали это без всяких опций в Хитрости второй.
—no-filename
Подавляет вывод имен файлов, когда задано несколько файлов для исследования.
Опция -I
Обрабатывает бинарные файлы как не содержащие совпадений с ОБРАЗЦОМ; эквивалент опции —binary-files=without-match.
Опция —include=ОБРАЗЕЦ_имени_файла
При рекурсивном исследовании директорий обследовать только файлы, содержащие в своем имени ОБРАЗЕЦ_имени_файла.
Опция -m ЧИСЛО_СТРОК
—max-count=ЧИСЛО_СТРОК
Прекратить обработку файла после того, как количество совпадений с ОБРАЗЦОМ достигнет ЧИСЛА_СТРОК:
grep -m 2 'kot' kot.txt kot kotoroe
Опция -y
Синоним опции -i (не различать верхний и нижний регистр символов).
Опции -U и -u применяются только под MS-DOS и MS-Windows, тут нечего о них говорить.
Опция —mmap
Использует системный вызов mmap вместо системного вызова read. Может дать лучшую производительность, а может привести к ошибкам. Это для продвинутых пользователей.
Опция -Z
—null
Если в выводе программы имена файлов (например при опции -l), то опция -Z после каждого имени файла выводит нулевой байт вместо символа новой строки (как обычно происходит). Это делает вывод однозначным, даже если имена файлов содержат символы новой строки. Эта опция может быть использована совместно с такими командами как: find -print0, perl -0, sort -z, xargs -0 для обработки файловых имен, составленных необычно, даже содержащих символы новой строки.
(Хотел бы я знать, как можно включить символ новой строки в имя файла. Если кто знает, не поленитесь — сообщите мне.)
Опция -z
—null-data
Рассматривает ввод как набор строк, каждая из которых заканчивается не символом новой строки, а нулевым байтом. Как и предыдущая опция, используется совместно с вышеперечисленными командами для обработки экзотических имен файлов.
Grep AND
5. Grep AND using -E ‘pattern1.*pattern2’
There is no AND operator in grep. But, you can simulate AND using grep -E option.
grep -E 'pattern1.*pattern2' filename grep -E 'pattern1.*pattern2|pattern2.*pattern1' filename
The following example will grep all the lines that contain both “Dev” and “Tech” in it (in the same order).
$ grep -E 'Dev.*Tech' employee.txt 200 Jason Developer Technology $5,500
The following example will grep all the lines that contain both “Manager” and “Sales” in it (in any order).
$ grep -E 'Manager.*Sales|Sales.*Manager' employee.txt
Note: Using regular expressions in grep is very powerful if you know how to use it effectively.
6. Grep AND using Multiple grep command
You can also use multiple grep command separated by pipe to simulate AND scenario.
grep -E 'pattern1' filename | grep -E 'pattern2'
The following example will grep all the lines that contain both “Manager” and “Sales” in the same line.
$ grep Manager employee.txt | grep Sales 100 Thomas Manager Sales $5,000 500 Randy Manager Sales $6,000
Использование egrep в Linux
Egrep или grep -E — это другая версия grep или Extended grep. Эта версия grep превосходна и быстра, когда дело доходит до поиска шаблона регулярных выражений, поскольку она обрабатывает метасимволы как есть и не заменяет их как строки. Egrep использует ERE или Extended Extended Expression.
Для этих целей истины созданы некоторые системы, основанные на описании текста при помощи шаблонов. К таким системам причисляются и постоянные выражения. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать бригаду egrep:
Есть возможность поиска по нескольким файлам и в подобном случае перед строкой выводится имя файла.
А следующий запрос выводит весь код, исключая строки, содержащие только комментарии:
В виде egrep, даже если вы не избегаете метасимволы, команда будет относиться к ним как к специальным символам и заменять их своим особым значением вместо того, чтобы рассматривать их как часть строки.
СИНТАКСИС GREP
Синтаксис команды выглядит следующим образом:
$ grep шаблон
Или:
$ команда | grep шаблон
- Опции — это дополнительные параметры, с помощью которых указывается различные настройки, поиска и вывода, например количество строк или режим инверсии.
- Шаблон — это любая строка или регулярное выражение, по которому будет вестись поиск
- Файл и команда — это то место где будет вестись поиск. Как вы увидите дальше grep позволяет искать в нескольких файлах и даже в каталоге используя рекурсивный режим.
Как видите grep умеет не только выполнять поиск в файлах linux, но и может фильтровать стандартный вывод, это очень удобная функция, когда нужно выбрать только ошибки из логов или найти PID процесса в многочисленном выводе утилиты ps.
Использование egrep в Linux
Egrep или grep -E — это другая версия grep или Extended grep. Эта версия grep превосходна и быстра, когда дело доходит до поиска шаблона регулярных выражений, поскольку она обрабатывает метасимволы как есть и не заменяет их как строки. Egrep использует ERE или Extended Extended Expression.
Для этих целей истины созданы некоторые системы, основанные на описании текста при помощи шаблонов. К таким системам причисляются и постоянные выражения. Два очень полезные спецсимвола — это ^ и $, которые обозначают начало и конец строки. Например, мы хотим получить всех пользователей, зарегистрированных в нашей системе, имя которых начинается на s. Тогда можно применить регулярное выражение «^s». Вы можете использовать бригаду egrep:
egrep «^s» /etc/passwd
Есть возможность поиска по нескольким файлам и в подобном случае перед строкой выводится имя файла.
egrep -i Hello ./example.cpp ./example2.cpp
А следующий запрос выводит весь код, исключая строки, содержащие только комментарии:
egrep -v ^/ ./example.cpp
В виде egrep, даже если вы не избегаете метасимволы, команда будет относиться к ним как к специальным символам и заменять их своим особым значением вместо того, чтобы рассматривать их как часть строки
ОПЦИИ
Начнём с того, что «grep» умеет не только фильтровать стандартный ввод , но и осуществлять поиск по файлам. По умолчанию «grep» будет искать только в файлах, находящихся в текущем каталоге, однако при помощи очень полезной опции можно сказать команде «grep» искать рекурсивно начиная с заданной директории.
GIST | По умолчанию команда «grep» чувствительна к регистру. Следующий пример показывает как можно искать и при этом не учитывать регистр, например «Adams» и «adams» одно и то же:
--ignore-case 'adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
John Adams, 1797-1801
GIST | Поиск наоборот (иногда говорят инвертный поиск), то есть будут выведены все строки, кроме имеющих вхождение указанного шаблона:
--invert-match 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
George Washington, 1789-1797 Thomas Jefferson, 1801-1809
GIST | Опции конечно же можно и нужно комбинировать друг с другом. Например поиск наоборот с выводом порядковых номеров строк с вхождениями:
--line-number --invert-match 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
1:George Washington, 1789-1797 3:Thomas Jefferson, 1801-1809
GIST | Раскраска. Иногда удобно, когда искомое нами слово подсвечивается цветом. Все это уже есть в «grep», остается только включить:
--line-number --color=always 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809
2:John Adams, 1797-1801
GIST | Мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда удобно вывести несколько строк из контекста. По умолчанию «grep» выводит лишь строку, в которой было найдено совпадение, но есть несколько опций, позволяющих заставить «grep» выводить больше. Для вывода нескольких строк (в нашем случае двух) после вхождения:
--color=always -A2 'Adams'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817
GIST | Аналогично для дополнительного вывода нескольких строк перед вхождением:
--color=always -B2 'James'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825
GIST | Однако чаще всего требуется выводить симметричный контекст, для этого есть ещё более сокращённая запись. Выведем по две строки как сверху так и снизу от вхождения:
--color=always -C2 'James'
George Washington, 1789-1797 John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825 John Quincy Adams, 1825-1829 Andrew Jackson, 1829-1837 Martin Van Buren, 1837-1841
John Adams, 1797-1801 Thomas Jefferson, 1801-1809 James Madison, 1809-1817 James Monroe, 1817-1825 John Quincy Adams, 1825-1829 Andrew Jackson, 1829-1837
GIST | Когда Вы ищете , то по умолчанию «grep» будет выводить также, , и тому подобные комбинации. Найдём только те строки, которые выключают именно всё слово целиком:
--word-regexp --color=always 'John'
John Fitzgerald Kennedy, 1961-1963 Lyndon Baines Johnson, 1963-1969
John Fitzgerald Kennedy, 1961-1963
GIST | Ну и напоследок если Вы просто хотите знать количество строк с совпадениями одним единственным числом, но при этом не выводить больше ничего:
--count --color=always 'John'
John Fitzgerald Kennedy, 1961-1963 Lyndon Baines Johnson, 1963-1969 Richard Milhous Nixon, 1969-1974
2
Стоит отметить, что у большинства опций есть двойник, например можно привести к более короткому виду и т.д.
Basic vs. extended regular expressions
In basic regular expressions the metacharacters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{, \|, \(, and \).
Traditional versions of egrep did not support the { metacharacter, and some egrep implementations support \{ instead, so portable scripts should avoid { in grep -E patterns and should use to match a literal {.
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification. For example, the command grep -E ‘{1’ searches for the two-character string {1 instead of reporting a syntax error in the regular expression. POSIX allows this behavior as an extension, but portable scripts should avoid it.
Синтаксис
grep ШАБЛОН
Ниже предоставлены основные опции утилиты.
-b — показывать номер блока перед строкой-c — Отключает стандартный способ вывода результата и вместо этого отображает только число обозначающее количество найденых строк.-h — не выводить имя файла в результатах поиска внутри файлов Linux-i — не учитывать регистр-l — отобразить только имена файлов, в которых найден шаблон-n — показывать номер строки в файле-s — не показывать сообщения об ошибках-v — инвертировать поиск, выдавать все строки кроме тех, что содержат шаблон-w — Ведет поиск по цельным словам. Например при обычном поиске строки ‘wood’ grep может найти слово ‘hollywood’. А если используется данный ключ то будут найдены только строки где есть слово ‘wood’-e — использовать регулярные выражения при поиске-An — показать вхождение и n строк до него-Bn — показать вхождение и n строк после него-Cn — показать n строк до и после вхождения-o — показать только совпадающие (непустые) части совпадающей строки, каждая из которых находится в отдельной строке.-P — Интерпретировать шаблон как регулярное выражение Perl. Это экспериментально, и grep -P может предупредить о невыполненных функции.-r — Производит поиск рекурсивно по всем поддиректориям.
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by and . It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is often not equivalent to ; it might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
Поиск полных слов
При поиске строки будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное не в словах), используйте параметр (или ).
Символов слова включают в себя буквенно — цифровые символы ( , и ) и подчеркивание ( ). Все остальные символы рассматриваются как несловесные символы.
Если вы выполните ту же команду, что и выше, включая опцию, команда вернет только те строки, которые включены в качестве отдельного слова.
Добавление контекста
Часто бывает полезно иметь возможность видеть некоторые дополнительные строки — возможно, несовпадающие — для каждой совпадающей строки. это может помочь определить, какие из совпадающих строк вам интересны.
Чтобы отобразить несколько строк после совпадающей строки, используйте параметр -A (после контекста). В этом примере мы запрашиваем три строки:
grep -A 3 -x "20-янв-06 15:24:35" geek-1.log
Чтобы увидеть некоторые строки перед совпадающей строкой, используйте (контекст перед) вариант.
grep -B 3 -x "20-янв-06 15:24:35" geek-1.log
И чтобы включить строки до и после совпадающей строки, используйте (контекст) вариант.
grep -C 3 -x "20-янв-06 15:24:35" geek-1.log