Этапы проектирования баз данных
Содержание:
- Правило 7. Тщательно выбирайте производные столбцы
- Правило 1: Какова природа приложения (OLTP или OLAP)?
- Виды баз данных и их структура, примеры
- Правило 5: Следите за данными, заполненные разделителями
- Правило 3: Не переусердствуйте с правилом 2
- Правило 4: Относитесь к дублирующим неоднородным данным как к своему главному врагу.
- Создаем базу данных
- Правило 2: Разбейте свои данные на логические части, упростите себе работу
- Концептуальная модель базы данных
- [править] Подходы к проектированию реляционных БД (РБД)
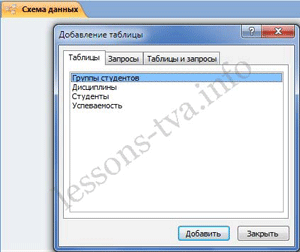
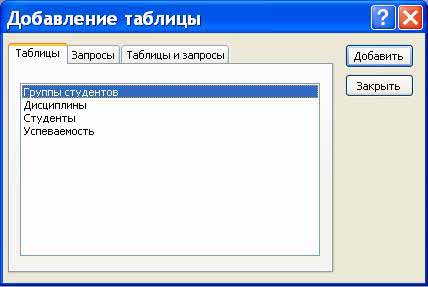
- 1 Анализ предметной области
- Подготовка эксперимента
- Правило 7. Тщательно выбирайте производные столбцы
- Создание связей между сущностями
- Этапы создания базы данных
- Правило 6: Следите за частичными зависимостями
- Azure Data Studio
- Запросы к базе данных и отчёты
- Литература
- Анализ предметной области
Правило 7. Тщательно выбирайте производные столбцы
Если вы работаете над приложениями OLTP, избавление от производных столбцов было бы хорошей мыслью, если только не существует веской причины для повышения производительности. В случае работы с OLAP, где нам нужно производить много сумм и вычислений, эти поля необходимы для повышения производительности.
На приведенном выше рисунке вы можете увидеть, как среднее поле зависит от меток и объекта. Это также одна из форм избыточности. Подумайте, действительно ли нужны поля, полученные из других полей?
Это правило также выражено в 3-й нормальной форме:«Ни один столбец не должен зависеть от других столбцов непервичного ключа». Не стоит применять это правило вслепую, так как не всегда избыточные данные плохие. Если избыточные данные являются расчетными данными, проанализируйте ситуацию, а затем решите, хотите ли вы реализовать третью нормальную форму.
Правило 1: Какова природа приложения (OLTP или OLAP)?
Когда вы начинаете разработку базы данных, первое, что нужно определить — природа приложения, которое вы разрабатываете: будет оно транзакционное или аналитическое? Многие разработчики находят применение трем нормальным формам не задумываясь о характере приложения, а затем у них возникают вопросы о том, как получить информацию о производительности и настройке. Как уже сказано выше, есть два вида приложений: основанные на транзакциях и аналитические. Давайте разберемся, что это за типы.
Транзакционный: в этом типе приложения ваш конечный пользователь больше интересуется четырьмя функциями CRUD: созданием, чтением, обновлением и удалением записей. Официальное название такой базы данных — OLTP.
Аналитический: в таких приложениях ваш конечный пользователь больше заинтересован в анализе, отчетности, прогнозировании и т. д. Эти типы баз данных имеют меньшее количество вставок и обновлений. Основная цель здесь — собрать и проанализировать данные как можно быстрее. Официальное название такой базы данных — OLAP.
Если вы считаете, что вставки, обновления и удаления будут использоваться чаще, то создайте нормализованный дизайн таблицы, или же создайте плоскую денормализованную структуру базы данных.
Ниже приведена простая диаграмма, показывающая, как имена и адрес в левой части составляют простую нормализованную таблицу. С помощью денормализованной структуры мы создали структуру плоской таблицы.
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
Правило 5: Следите за данными, заполненные разделителями
Второе правило 1-й нормальной формы говорит избегать повторения групп. Пример повторяющихся групп отображен на рисунке ниже. Если вы внимательно изучите поле «Syllabus», то увидите, что там слишком много данных. Эти поля называются «Повторяющиеся группы». Если нам нужно манипулировать этими данными, запрос будет сложным, а производительность запросов оставит желать лучшего.
Эти типы столбцов, которые имеют заполненные разделителями данные, нуждаются в особом внимании, и лучшим подходом было бы переместить эти поля в другую таблицу и связать их с ключами для лучшего управления.
Итак, теперь применим второе правило 1-й нормальной формы: «Избегайте повторения групп». Вы можете видеть на приведенном выше рисунке, что мы создали отдельную таблицу учебных планов — Syllabus Table, а затем сделал отношение «многие ко многим» (many-to-many relationship) к таблице предметов — Subject Table.
При таком подходе поле «Syllabus» в основной таблице больше не повторяется и имеет разделители данных.
Правило 3: Не переусердствуйте с правилом 2
Разработчики — люди, зачастую воспринимающие все буквально. Если вы скажете им как нужно делать, они будут делать только так и могут переусердствовать, что может привести к нежелательным последствиям. Это также относится к правилу 2, о котором мы только что говорили выше. Когда вы думаете о декомпозиции, остановитесь и спросите себя, насколько она нужна? Разложение должно быть обдуманным и логичным.
Например,ниже вы видите поле номера телефона. Вряд ли вы часто будете использовать коды ISD для телефонных номеров отдельно (пока ваша заявка не потребует этого). Поэтому было бы разумным решением не разбивать его, поскольку это может привести к большему количеству осложнений.
Правило 4: Относитесь к дублирующим неоднородным данным как к своему главному врагу.
Соберите и обработайте дубликаты данных. Основная проблема относительно повторяющихся данных заключается не в том, что требуется пространство на жестком диске, а в путанице, которую они создают.
Например, на приведенной ниже таблице вы можете заметить, что «5th Standard» и «Fifth standard» означает то же самое.Возможно данные попали в систему из-за плохого ввода данных или плохой проверки. Если вы когда-либо захотите получить отчет, они будут отображаться как разные объекты, что очень сбивает с толку.
Одно из возможных решений — перемещение в другую основную таблицу и их передача через внешние ключи. На рисунке ниже показано, мы создали новую главную таблицу под названием «Standards» и связали ее с помощью простого внешнего ключа.
Создаем базу данных
Управление базами данных как объектами
Будем считать, что наша небольшая экскурсия по запросам и командам SQL со стороны «торгового зала» завершена. Заглянем теперь в его «служебные помещения» и познакомимся с тем, как создается сама база данных. Эта часть языка SQL не столь стандартизирована и сильно отличается в различных реализациях. Поэтому в дальнейших примерах я буду придерживаться синтаксиса, принятого в самой популярной на веб-серверах системе — MySQL.
MySQL — продукт шведской компании MySQL AB. Ее основатели — Дэвид Аксмарк, Аллан Ларсон и Майкл Видениус (последний больше известен по прозвищу — Монти). По одной из версий, первая часть названия продукта (My) — не что иное, как англизированная запись имени дочери М. Видениуса. Однако точно за происхождение названия сегодня не могут поручиться даже отцы-создатели. Существует версия, по которой «my» — это префикс, с которого начинались названия рабочих каталогов на их компьютерах.
Из всех команд чаще всего нам будут нужны три: CREATE (создать), ALTER (изменить) и DROP (уничтожить).
Чтобы создать новую базу данных с названием, ну скажем, OUR_SHOP, следует выполнить команду:
Еще лучше сразу при ее создании установить нужную кодировку (ведь по умолчанию в MySQL используется latin1). В итоге команда будет выглядеть так.
Если вы забыли сделать это сразу, не беда. Для того и существуют команды по изменению:
Когда, наигравшись вдоволь с пробной базой данных, вы захотите ее уничтожить, воспользуйтесь командой:
Управление таблицами
Чтобы создать таблицу GOODS, на которой мы отрабатывали манипуляции с данными, потребуется составить команду примерно такого вида:
Разберем эту команду подробнее. Тип INT устанавливается для столбцов с целочисленными данными, тип VARCHAR(100) обеспечивает хранение строк с длиной не более 100 символов, DECIMAL(10,2) соответствует действительным числам с не более чем десятью знаками и точностью в два знака после запятой.
Столбец ID объявлен первичным ключом (PRIMARY KEY).
Ключевое слово AUTO_INCREMENT означает, что при добавлении новых строк с неуказанным значением ID оно будет автоматически заполняться следующим значением. Это удобно, поскольку обычно нет нужды вручную указывать значения первичных ключей, а за тем, чтобы они были уникальными, пусть лучше следит база данных.
NOT NULL означает запрет на пустые значения в столбце, иными словами, гарантирует обязательность заполнения.
Команда DEFAULT задает значение по умолчанию — то, которое будет записываться в базу при добавлении новой строки, если не указано иное. В нашем случае она обеспечивает автоматическое объявление товара штучным (код = 1) в случае, если при добавлении новых строк не будет указан другой код.
Признак UNIQUE обеспечивает уникальность значений в колонке (в нашем случае — уникальность названий товаров).
Если в будущем вы захотите перенастроить объявленные командой CREATE столбцы таблицы, сделать это можно командой ALTER. Например, таблицу GOODS можно нарастить строчной колонкой REMARK (подкоманда ADD):
Поработав с ней немного и убедившись, что 50 символов для примечания явно недостаточно, увеличиваем максимальный размер строки до 250 (блок CHANGE):
Так как имя столбца мы не изменяли (новое совпадает со старым), то его просто повторяем в этой команде (как бы меняем само на себя).
И наконец, убедившись через какое-то время, что без примечания в товарном справочнике вполне можно обойтись, мы удаляем ставшую ненужной колонку (блок DROP):
Удалить таблицу целиком можно командой DROP:
Стоит ли говорить о том, что пользоваться командами с этим ключевым словом следует с особой осторожностью?
Правило 2: Разбейте свои данные на логические части, упростите себе работу
Это правило на самом деле является первым правилом из 1-й нормальной формы. Одним из признаков нарушения этого правила является то, что ваши запросы используют слишком много функций синтаксического анализа, таких как SUBSTRING, CHARINDEX и т. д., Тогда, вероятно, это правило необходимо применять.
К примеру, ниже приведена таблица с именами учеников. Если вам понадобится запросить имена учеников,, содержащих «Koirala», но не содержащих «Harisingh», представьте, какой запрос вы получите.
Поэтому лучше было бы разбить это поле на логические части, чтобы мы могли писать чистые и оптимальные запросы.
Концептуальная модель базы данных
Под концептуальной моделью понимают отражение предметной области для разрабатываемой базы данных. Если не вдаваться в теорию, то речь идёт о некой диаграмме с общепринятыми обозначениями:
— вещи обозначаются прямоугольниками;
— атрибуты объекта овалами;
— связи в таблицах ромбами;
— мощность и направление связей стрелками (одинарными, двойными).
Делая поставку, поставщик подтверждает её документами. Аналогично и с покупателем. Таким образом, и поставку, и покупку можно рассматривать в качестве самостоятельных объектов.
Итого 5 объектов и 4 связи. Из них:
— 2 связи типа «один ко многим» (один поставщик может делать несколько поставок; один покупатель может делать несколько покупок);
— 2 связи типа «многие ко многим» (каждая поставка может включать несколько товаров, причём одинаковый товар может быть в нескольких поставках; аналогичная ситуация по линии «Покупка — Товар»).
Но давайте вспомним, что связи типа «многие ко многим» недопустимы в реляционных моделях данных, поэтому такие связи надо менять на связи типа «один ко многим». Делаем это, добавляя промежуточный объект:
Видим, что в структуре появились ещё 2 объекта — «Журнал поставок» и «Журнал покупок» со связями типа «один ко многим» (каждый журнал может включать несколько поставок/покупок, но каждая поставка/покупка включает лишь один журнал).
[править] Подходы к проектированию реляционных БД (РБД)
Первый подход (предложен Э. Коддом) основан на понятии «универсального отношения», то есть таблицы, состоящей из всех атрибутов предметной области (ПО). В дальнейшем такая таблица разбивается путем декомпозиции на несколько взаимосвязанных нормализованных таблиц. В результате на этапе концептуального проектирования создается реляционная схема БД.
Второй подход (объектный подход) основан на создании концептуальной модели данных, состоящей из описания объектов ПО и связей между ними. Затем эта модель преобразуется в реляционную модель. Процесс преобразования автоматически гарантирует получение нормализованной реляционной схемы БД.
1 Анализ предметной области
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.
Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.
Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
Подготовка эксперимента
Вышеизложенные теоретические рассуждения хотелось бы проверить на практике – это и было целью возникшей на долгих выходных задумки. Для этого необходимо оценить скорость работы нашего «условного приложения» во всех описанных сценариях использования базы, а также рост этого времени с ростом размера социальной сети (n). Целевым параметром, который нас интересует и который мы будем замерять в ходе эксперимента, является время, затраченное «условным приложением», на выполнение одной «бизнес-операции». Под «бизнес-операцией» мы понимаем одну из следующих:
- Добавление одного нового друга
- Проверка, является ли пользователь А другом пользователя Б
- Удаление одного друга
Таким образом, с учетом обозначенных в изначальной постановке требований, сценарий проверки вырисовывается следующий:
- Запись данных. Сгенерировать случайным образом исходную сеть размером n. Для большего приближения к «реальному миру» количество друзей у каждого пользователя – так же случайная величина. Замерить время, за которое наше «условное приложение» запишет в HBase все сгенерированные данные. Потом полученное время разделить на общее количество добавленных друзей – так мы получим среднее время на одну «бизнес-операцию»
- Чтение данных. Для каждого пользователя составить список «личностей», для которых надо получить ответ, подписан ли на них пользователь или нет. Длина списка = примерно кол-ву друзей пользователя, причем для половины проверяемых друзей ответ должен быть «Да», а для другой половины – «Нет». Проверка производится в таком порядке, чтобы ответы «Да» и «Нет» чередовались (то есть в каждом втором случае нам придется перебирать все колонки строки для вариантов 1 и 2). Общее время проверки затем разделить на количество проверяемых друзей для получения среднего времени на проверку одного субъекта.
- Удаление данных. Удалить у пользователя всех друзей. Причем порядок удаления – случайный (то есть «перемешиваем» изначальный список, использовавшийся для записи данных). Общее время проверки затем разделить на количество удаляемых друзей для получения среднего времени на одну проверку.
Сценарии необходимо прогнать для каждого из 5 вариантов моделей данных и для разных размеров социальной сети, чтобы посмотреть, как меняется время с ее ростом. В рамках одного n связи в сети и список пользователей для проверки должны быть, естественно, одинаковыми для всех 5 вариантов.
Для лучшего понимания ниже привожу пример сгенерированных данных для n= 5. Написанный «генератор» дает на выходе три словаря ID-шников:
- первый – для вставки
- второй – для проверки
- третий – для удаления
Как можно заметить, все ID, большие 10 000 в словаре для проверки – это как раз те, которые заведомо дадут ответ False. Вставка, проверка и удаление «друзей» производятся именно в указанной в словаре последовательности.
С учетом вычислительной мощности конкретного ноутбука экспериментально был выбран запуск для n = 10, 30, …. 170 – когда общее время работы полного цикла тестирования (все сценарии для всех вариантов для всех n) было еще более-менее разумным и умещалось во время одного чаепития (в среднем 15 минут).
Тут необходимо сделать ремарку, что в данном эксперименте мы в первую очередь оцениваем не абсолютные цифры производительности. Даже относительное сравнение разных двух вариантов может быть не совсем корректным. Сейчас нас интересует именно характер изменения времени в зависимости от n, так как с учетом указанной выше конфигурации «тестового стенда» получить временные оценки, «очищенные» от влияния случайных и прочих факторов, очень сложно (да и такой задачи не ставилось).
Правило 7. Тщательно выбирайте производные столбцы
Если вы работаете над приложениями OLTP, избавление от производных столбцов было бы хорошей мыслью, если только не существует веской причины для повышения производительности. В случае работы с OLAP, где нам нужно производить много сумм и вычислений, эти поля необходимы для повышения производительности.
На приведенном выше рисунке вы можете увидеть, как среднее поле зависит от меток и объекта. Это также одна из форм избыточности. Подумайте, действительно ли нужны поля, полученные из других полей?
Это правило также выражено в 3-й нормальной форме:«Ни один столбец не должен зависеть от других столбцов непервичного ключа». Не стоит применять это правило вслепую, так как не всегда избыточные данные плохие. Если избыточные данные являются расчетными данными, проанализируйте ситуацию, а затем решите, хотите ли вы реализовать третью нормальную форму.
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:
1:1
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:
1:Mодной1
Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:
один-ко-многим
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:
Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:
один не может существовать без другого
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза
Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями»
Так как единственный способ, которым ученикам назначают учителей — это предметы.
Этапы создания базы данных
Надлежащим образом структурированная база данных:
- Помогает сэкономить дисковое пространство за счет исключения лишних данных;
- Поддерживает точность и целостность данных;
- Обеспечивает удобный доступ к данным.
Основные этапы разработки базы данных:
- Анализ требований или определение цели базы данных;
- Организация данных в таблицах;
- Указание первичных ключей и анализ связей;
- Нормализация таблиц.
Рассмотрим каждый этап проектирования баз данных подробнее
Обратите внимание, что в этом руководстве рассматривается реляционная модель базы данных Эдгара Кодда, написанная на языке SQL (а не иерархическая, сетевая или объектная модели)
Правило 6: Следите за частичными зависимостями
Следите за полями, которые частично зависят от первичных ключей. Например, в приведенной выше таблице мы видим, что первичный ключ создается с номером и стандартом. Теперь внимательно посмотрите на поле «Syllabus»: оно связано со стандартом, а не со студентом напрямую (roll number).
Учебный план (syllabus) связан со стандартом, по которому учится студент, а не непосредственно со студентом. Поэтому, если завтра мы хотим обновить учебный план, мы должны обновить ее для каждого учащегося, что кропотливо и нелогично. Имеет смысл перемещать эти поля и связывать их со стандартной таблицей.
Посмотрите, как мы переместили поле Syllabus и привязали его к таблице стандартов.
Это правило не что иное, как 2-я нормальная форма: «Все ключи должны зависеть от полного первичного ключа, а не частично».
Azure Data Studio
Azure Data Studio – это бесплатный, кроссплатформенный инструмент с открытым исходным кодом для работы с базами данных Microsoft SQL Server.
Azure Data Studio основана на Visual Studio Code и ориентирована на SQL разработчиков, так как основное назначение Azure Data Studio – это написание, редактирование и выполнение SQL запросов, иными словами, это редактор SQL кода.
Azure Data Studio позволяет работать с базами данных Microsoft SQL Server, SQL Azure, а также с другими СУБД, например, с PostgreSQL
Основные особенности
Инструмент бесплатный
Кроссплатформенность (поддержка Windows, Linux, macOS)
Ориентация на SQL разработчиков
Продвинутый SQL редактор (технология IntelliSense, фрагменты SQL кода)
Расширяемость (встроенная поддержка расширений)
Работа с другими СУБД
Встроенная возможность выгрузки данных в формат Excel, XML, JSON, CSV
Группировка подключений к серверам
Визуализация данных с помощью диаграмм и графиков
Поддержка нескольких цветовых тем
Встроенный терминал (Bash, PowerShell, sqlcmd)
Записные книжки
Недостатки
Отсутствует конструктор таблиц
Нет функционала для работы со свойствами объектов
Отсутствует возможность управления безопасностью
Отсутствует возможность импорта и экспорта DACPAC
Отсутствует функционал для большинства задач администрирования
Мне нравится4Не нравится
Запросы к базе данных и отчёты
Запросы:
- доступность выбираемого в селекторе препарата в выбираемой в селекторе аптеке на данный момент времени;
- группы препаратов, которых нет в выбираемой в селекторе аптеке на данный момент времени;
- аптеки, в которых есть дефицит любого препарата по введённой дате;
- покупки препаратов, которые есть на витринах аптек по введённой дате с указанием препаратов и аптек;
- клиенты, совершившие покупки в выбранной в селекторе аптеке по введённой дате.
Отчёты:
- о количестве покупок со списком аптек по введённой дате с указанием сумм;
- о продажах выбранного препарата во всех аптеках по введённой дате;
- о проданных препаратах стоимостью более 150 рублей по введённой дате;
- о препаратах, которые есть на витрине во всех аптеках;
- о клиентах, зарегистрированных в определённый интервал времени.
Поделиться с друзьями
Реляционные базы данных и язык SQL
Литература
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — 1328 с. — ISBN 0-321-19784-4.
- Когаловский М.Р. Перспективные технологии информационных систем. — М.: ДМК Пресс; Компания АйТи, 2003. — 288 с. — ISBN 5-279-02276-4.
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: «Вильямс», 2003. — 1436 с. — ISBN 0-201-70857-4.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс. — М.: «Вильямс», 2003. — 1088 с. — ISBN 5-8459-0384-X.
Анализ предметной области
Компания — заказчик информационной системы, использующей базу данных — сеть аптек, расположенных в одном городе, осуществляет розничную торговлю лекарственными препаратами как по рецептам, так и без рецептов.
В любой из аптек сети клиент может приобрести лекарственный препарат, имеющийся в наличии в данной аптеке, а может и заказать препарат, который отсутствует в данной аптеке. В последнем случае есть возможность заказать необходимый препарат и в зависимости от условий (препарат имеется в наличии в одной из других аптек, на складе или же его необходимо получить у поставщика) принимается решение доставить отсутствующий препарат в тот же день, на следующий день или в течении нескольких ближайших дней. Часть препаратов находятся на витрине аптеки.
В каждой из аптек регистрируется покупка каждой единицы препарата и все покупки, совершённые одним клиентом в одной аптеки в один момент времени, прикрепляются к корзине покупок.
Пользователями системы являются сотрудники сети аптек, в чьи обязанности входит учёт и анализ сделок (сотрудники служб маркетинга), обслуживание клиентов (продавцы). Кроме того, ряд функций системы (получение выборок данных с суммами, вырученными от продаж) могут быть запрошены и бухгалтерами сети аптек, так как бухгалтерия данной сети централизована, то есть, в каждой аптеке нет своей бухгалтерии.
Требуемыми функциями системы, использующей базу данных, являются:
- регистрация всех продаж в каждой аптеке;
- формирование корзины покупок, на основе которой выдаётся квитанция клиентам;
- учёт продаж, проданных препаратов и групп, к которым принадлежат препараты, а также дефицита препаратов в каждой аптеке (если затребованный клиентом препарат в данное время отсутствует в аптеке);
- оперативный учёт;
- статистический и сравнительный анализ данных о препаратах и продажах, о дефиците и результатах его ликвидации.